Linux将内存分为两部分:用户空间和内核空间。用户空间的程序无法访问内核空间的数据,反之依然,所以他们之间的指针无法直接使用。用户程序想访问内核空间,比如网络,文件系统的数据,则需要通过系统调用的方式进入内核空间。
在不同的空间时,CPU运行的环境是不同,然后有了上下文的概念。CPU总处于以下状态中的一种:
1)内核态,运行于进程上下文,内核代表进程运行于内核空间。
2)内核态,运行于中断上下文,内核代表硬件运行于内核空间。
3) 用户态, 运行于进程上文件的用户空间。
进程上下文
一个进程的上下文可以分为三个部分:用户级上下文、寄存器上下文以及系统级上下文:
1) 用户级上下文: 正文、数据、用户堆栈以及共享存储区;
2) 寄存器上下文: 通用寄存器、程序寄存器(IP)、处理器状态寄存器(EFLAGS)、栈指针(ESP);
3) 系统级上下文: 进程控制块task_struct、内存管理信息(mm_struct、vm_area_struct、pgd、pte)、内核栈等。
在进程调度的,系统需要将上面全部的信息进行切换,新的进程才可以运行。
#### 模式切换
我们常说的系统调用,只是当前进程上下文从用户态进入内核态,只有寄存器上下文进行了切换。相对进程切换要简单很多。通过数据观察,模式切换不在vmstat的cs列统计中。
http://blog.51cto.com/guojuanjun/1951816
中断上下文
CPU接收到硬件的中断信号, 则切换到中断上下文,进入内核态。由于中断处理程序只会运行在内核态,而且与进程无关。(中断处理程序不能睡眠,没有进程调度单元,睡了就没法唤醒了)。所以进程上下文切换到中断上下文时, 进程上下文的第一部分用户级上下文不需要切换。
那vmstat的cs是否包含中断上下文的切换呢,如图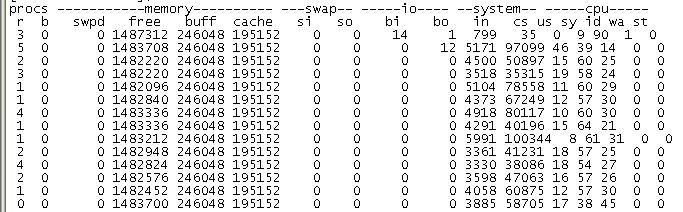
通过这个数据观察, in(中断数)明显小于cs(上下文切换数)。 通常情况下,每次中断都会产生到中断上下文的切换,in不应该小于cs。反证可知,cs列不包括到中断产生的切换。
综上所述:vmstat中的cs列只包括进程上下文的切换。
进程调度程序只能运行在内核态,所以进程调度也只会发生在内核态:
1) 用户态进程无法实现主动调度。只有通过系统调用进入内核态,在系统调用处理完,返回用户态时,是一个调度点。这个时候会检测有没有设置NEED_RESCHED标志。
2) 若用户态进程没有系统调用,则通过中断处理程序返回时进行被动调度。
3) 内核进程可直接调用schedule()进行主动调度。